ビジネスに活用するための解析を理解して、データ準備の程度が決まります
タグ付け、データの統合、データクレンジング等、様々な手法があります
特集概略

皆さんの組織にはどんなデータがありますか?それらはすぐにビジネスに活かせるようになっていますか?これはデータ活用を開始する前によく問いかけられる質問です。いかがでしょうか、皆さんは即答できるでしょうか。
実はこの質問にハッキリと答えるのは難問です。そもそも、どんなデータがあれば組織の役立つのかという議論の前に、どんな事をしたいのか、現状はどうなっているかを把握しておかないと、やりたい事と現状とのギャップがわからず、どんな解決方法が適当であるかの議論にたどり着けません。ここまでの議論ができると、やっとその解決方法をとるために必要なデータは組織内にあるだろうか。あるいは現状はデータがないとしても、これから取得、あるいは生成可能だろうか、という検討へ進みます。
組織の中はデータ発生源が無数にあります。必要そうなデータが特定できても、それらが実際問題として生成可能かという問題があります。例えば、何かの製造装置の状態を把握する必要があるが、この装置がとても古くアナログメーターしかないような場合はどうでしょうか。アナログメーターをカメラで常時観測して、そのデータを画像解析する必要があるかもしれません。
また部署によって、同じような記録でも、まったく別々のExcelの形式で保存されているようなケースも多くみられます。ご存じのように、基本的にはデータ解析などを行う場合には、データはなるべくたくさんあったほうが解析結果の精度向上が期待できます。ところが、同じExcelでも記載のしかたがバラバラだと、それらを統一することが必要になります。そして、その作業は人間が行うには量の多さから、限界があります。
こうした背景の中、近年では様々なデータを使えるデータに変換するための作業を一括で行える自動化ツール(RPA:Robotic Process Automation)なども登場しています。
この特集では、データ生成から、データの欠損などを補完するデータ整備を行い使えるデータにするための事例や支援サービスをご紹介しています。
関連する商品・サービス・事例(データ処理の自動化を用いた作業工数の削減)
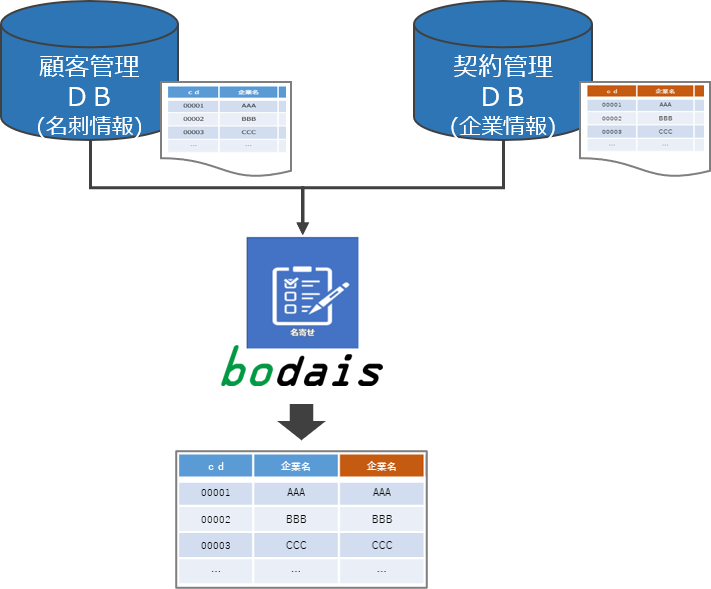
この事例ではデータ作りの一例として、顧客データと契約データの名寄せ、突合を自動化処理を行い、作業工数の削減を実現した事例です。データ間の名寄せには様々な方法がありますが、この事例では完全一致していない場合にも対応できるように「レーベンシュタイン距離」と呼ばれる指標を計算することで、名簿間の類似度を定量的に表しています。
事例概要
この事例で取り扱った課題は、
・営業リストの重複チェックや複数のリストの統合を自動化する
・文字列が完全一致しなくても類似度スコアで重複を判定可能に
する
・データの入力不備による目視作業が必要だった点の効率化を実
現する
というものでした。名寄せ処理に使用するデータは、顧客管理マスタの元となる名刺情報データ(22.5万件)と国税庁にて公開されている法人情報(約448万件)を利用。さらに、独自の名寄せエンジンを活用することで、これまで特定の難しかった“OCRで正しく読み取りができていないデータ”の処理において、従来の方法よりも優位であることを実証しました。
事例へのリンク
ご紹介した「データ処理自動化を用いた作業工数の削減」はこちらからより詳しい情報をご覧いただけます。

データ処理自動化を用いた作業工数の削減
顧客データおよび契約データの処理自動化によって作業工数を削減
PoC/受託解析
- 情報通信業
関連する商品・サービス・事例(マテリアル・インフォマティクスの推進)
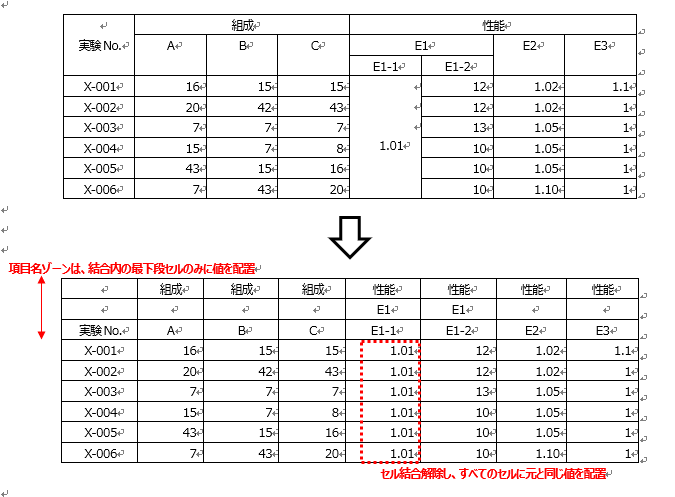
データ整備には様々な処理がありますが、実験データなどの膨大な結果を同じ形式に統合してけら教師データや、機械学習に利用するといったことが行われます。この事例は、ファイル形式、項目、記載内容がバラバラな実験ログデータの形式を整えることで機械学習等に活用できるデータ化を実施したものです。加えて、記載内容の統一化のために同義語項目統合のための辞書作りも行っています。組織内に統一されていない実験データを統合する場合には有益な事例といえます。
事例概要
マテリアルインフォマティクス(MI)を進めるためには膨大な過去の実験データを取り込んで学習させる必要がありました。そこでこの組織では、まず膨大なデータがどのような形式で保存されているかを調査し、それらをどのように変換すれば形式を統一できるか、ということに取り組みました。人間であれば目視で異なる表に記載された項目が同じ意味なのかを瞬時に判断できますが、自動的に行うが困難であったが、最終的にはデータを統一する独自のプログラムを作成し、統一化を行う作業を効率的に実施できるようになりました。
事例へのリンク
ご紹介した「マテリアル・インフォマティクスの推進」はこちらからより詳しい情報をご覧いただけます。
マテリアル・インフォマティクスの推進
実験ログデータの整形によってマテリアル・インフォマティクスを推進
PoC/受託解析
- 製造業
関連する商品・サービス・事例(データクレンジング)
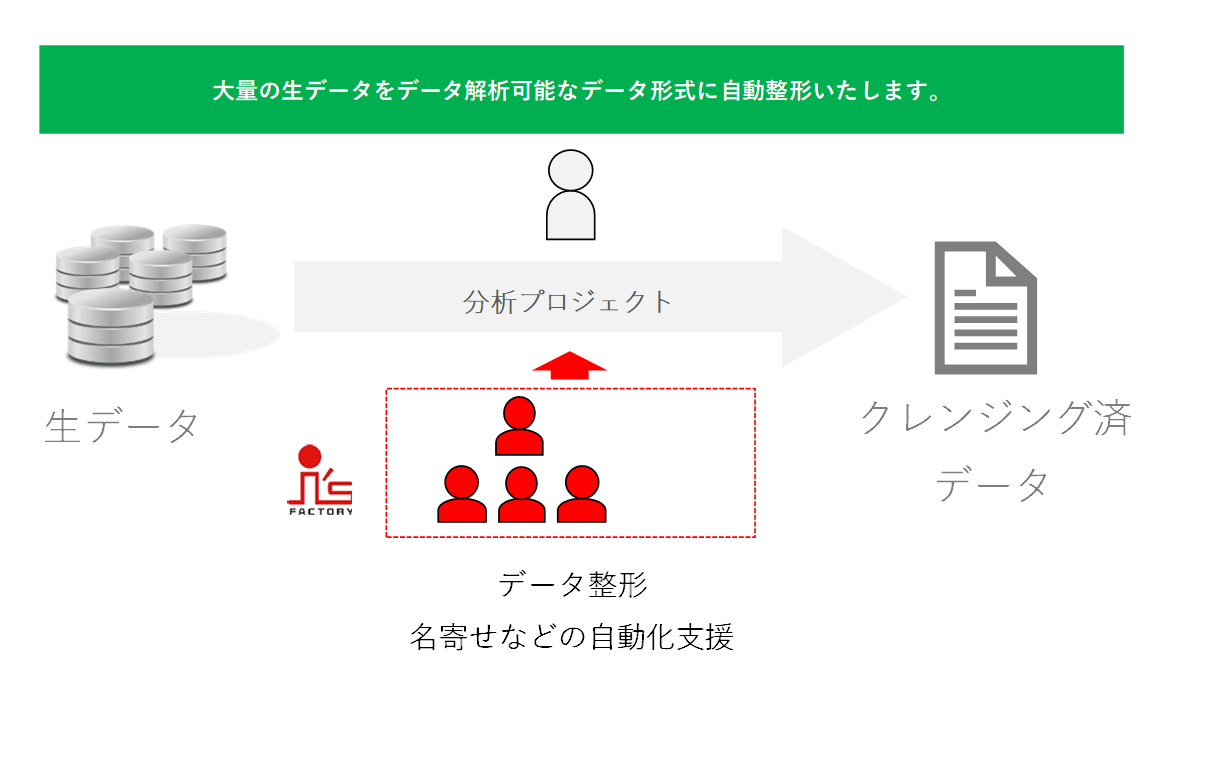
データ整備の一つでよく行われる作業1つがデータクレンジングです。データ解析の準備として必要なデータ加工一式のことを意味しています。実際の作業は、各環境によって多少異なりますが、データ解析をこれから初めて行う。プロの準備を実際に見てみたいという要望にも好適のようです。
サービス概要
データ解析の時間よりも、データを準備する時間や、整備する時間の方が長くかかることもしばしばです。そこで、解析プロジェクトのマネージャークラスのスタッフによるヒアリング、顧客企業に訪問する現地でのクレンジング作業により、安心・スピーディに作業を実施。また、実際のクレンジング作業を見ながら進められるので、教育要素も含まれているサービスです。
サービスへのリンク
ご紹介した「データクレンジング」はこちらからより詳しい情報をご覧いただけます。

データクレンジング
面倒なデータクレンジングを専業プロが行います
人材教育
- 株式会社アイズファクトリー
関連する商品・サービス・事例(タグ付けシステム開発)
データ整備を行っていく過程では、特定のタグやフラグをつけていくことがあります。このサービスも手作業で行うには単調で膨大なことから、なるべく自動化したい作業の1つです。このサービスではそうしたニーズに応えてくれるものです。
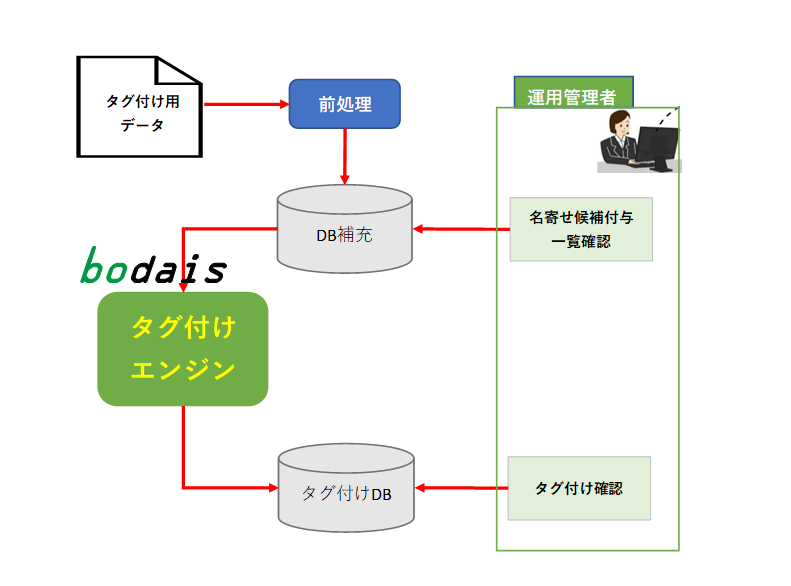
サービス概要
このサービスでは、人的に行っているタグ付け作業をシステム化したり、人間による恣意的なタグ付けではなく、恣意性のない合理的なタグ付けを実現することを支援してくれます。
このサービスへのリンク
ご紹介した「タグ付けシステム開発」はこちらからより詳しい情報をご覧いただけます。
タグ付けシステム開発
恣意性のない効率的なタグ付けができます
システム
- 株式会社アイズファクトリー
関連する商品・サービス・事例(データ識別自動判定)
1つのデータのセットには、いくつもの項目が含まれていることが一般的です。この項目は住所で、これは顧客名のよみがなである、といったものです。人間の目では、これらの項目の意味も瞬時に理解できることも多いですが、項目数が増えたりデータ量が増えるで人力では非常に不便です。そこで、このサービスでは自動で、データ項目の識別、判別、そして適宜の形式に出力するサービスです。
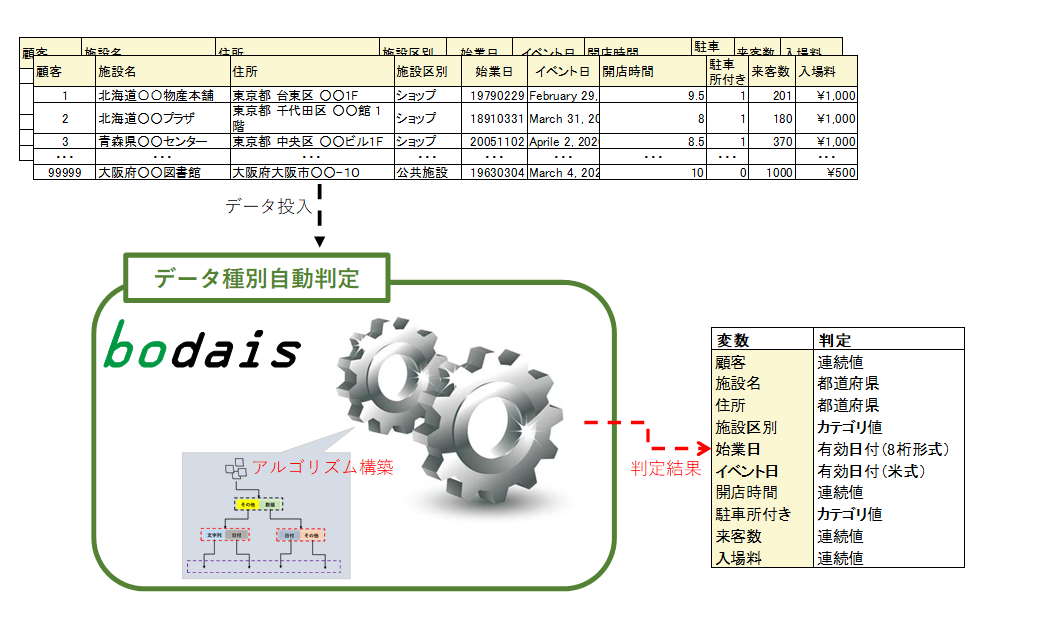
サービス概要
大量のデータから、データ項目の識別と、適宜の数値等への変換、出力といった一連の作業を自動的に行うシステムを構築するサービスです。
この事例へのリンク
ご紹介した「データ識別自動判定」はこちらからより詳しい情報をご覧いただけます。
データ種別自動判定
膨大なデータの種別判断の負担を減らします
システム
- 株式会社アイズファクトリー
この特集に関連する用語
ここでご紹介したサービス事例等に関連する用語をご紹介します。是非、こちらもご参照ください。
用語へのリンク
ご紹介した「用語」や関連する「用語」はこちらからより詳しい情報をご覧いただけます。
データ整備
- 【英語】Data Maintenance
- 【読み】データセイビ
データ解析
名寄せ
- 【英語】Aggregation of names
- 【読み】ナヨセ
技術研究
レーベンシュタイン距離
- 【英語】Levenshtein Distance
- 【読み】レーベンシュタインキョリ
データ解析
データクレンジング
- 【英語】Data Cleaning
- 【読み】データクレンジング
データ解析
欠損処理
- 【英語】Missing Processing
- 【読み】ケッソンショリ
データ解析
大量文書データの検索・可視化
- 【英語】Missing Value Imputation
- 【読み】ケッソンチホカン
データ解析

大量文書データの検索・可視化
大量のテキストデータを、キーワードを通じて関係づけて活用しやすくする
データ解析
- 株式会社アイズファクトリー

店舗情報の整合性向上(DWH構築)
DWH構築によって店舗情報の整合性が向上
DWH構築
- 情報通信業
データ分析効率化のためのDWH構築
DWH構築によって分析がスピードアップ
DWH構築
- 医療,福祉