顧客データおよび契約データの処理自動化によって作業工数を削減
営業リストの重複チェックや複数のリストの統合を自動化
文字列が完全一致しなくても類似度スコアで重複を判定
データの入力不備で目視が必要だった作業を効率化
文字列が完全一致しなくても類似度スコアで重複を判定
データの入力不備で目視が必要だった作業を効率化
目次
事例詳細
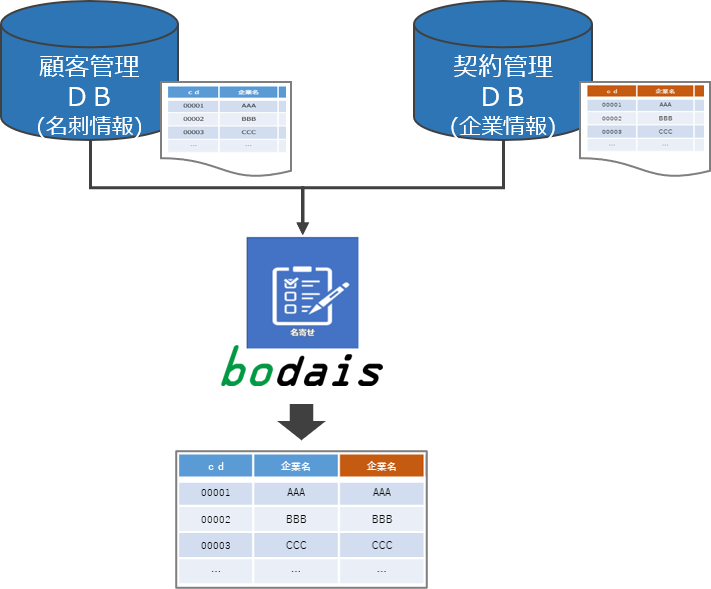
顧客データの名寄せ作業および顧客データと契約データの突合作業を自動化した。従来は「人手+ツール」で実施していた作業を自動化することによって工数が削減された。
経緯等
・名寄せのアルゴリズムにはレーベンシュタイン距離を採用しており、名寄せ元の文字列と名寄せ先の文字列の類似度をスコアとして算出し、一番類似度の高い文字列同士を名寄せする仕組みを構築した。
・名寄せ処理に使用するデータは、顧客管理マスタの元となる名刺情報データ(22.5万件)と国税庁にて公開されている法人情報(約448万件)。
・名寄せエンジンを活用することで、これまで特定の難しかった“OCRで正しく読み取りができていないデータ”の処理において、従来の方法よりも優位であることが証明された。