
目次
確率的潜在意味解析(PLSA)とは
確率的潜在意味解析(PLSA)とは、比較的疎な高次元(列数の多い)データを低次元(列数の少ない)データに圧縮し、教師なしクラスタリングを実施する技術のことです。
主な利用方法として、文章分類に使われます。文章分類では、一般的に、文章に出現する単語の種類は多いため、単語文書行列は、疎(スパース)行列になります。
PLSAでは、このような疎行列でも低次元へ圧縮することにより、文章間の類似度を算出したり、文章のトピック(話題)に分類分けできます。
また、それぞれのトピックに所属する確率が算出できるソフトクラスタリングに属します。文章ごとの所属クラスタが確率的に求まるため、分析結果の応用範囲も広がります。
確率的潜在意味解析(PLSA)のフロー
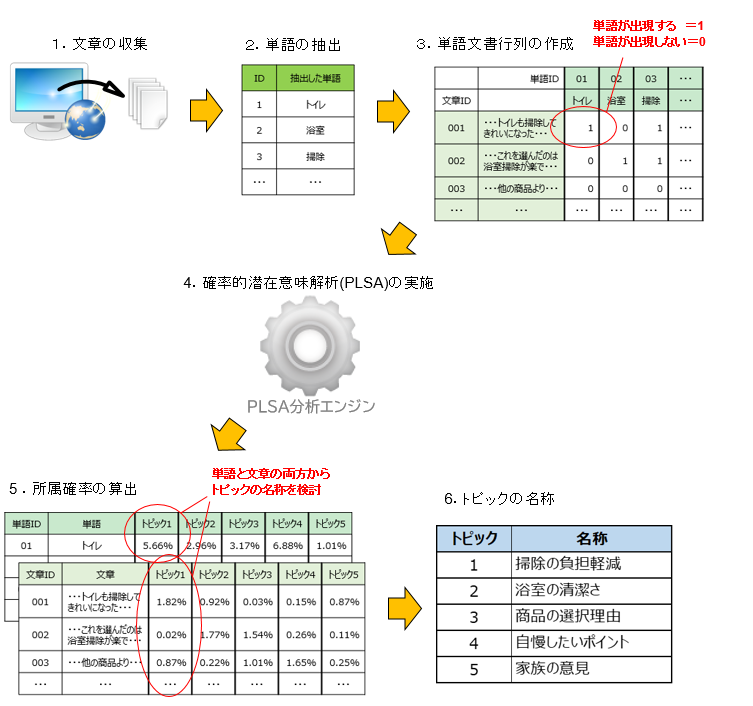
(1) 多数の文章(IDとテキスト文の対)を入力データとする
(2) 形態素分析や複合語分析などにより、文章の出現単語を抽出する
(3) 文章IDを行とし、出現単語IDを列とする単語文書行列を作成する。必要に応じ、tf-idfなどの前処理も実施する
(4) 単語文書行列を入力として、確率的潜在意味解析(PLSA)を実施する。ここで、トピック数は、分析者が決定するパラメータである
(5) 所属確率結果の算出。PLSAにより得られた結果の妥当性の判断をする。トピックごとの単語や文書分類の結果を読み解き、トピック数の調整を行う
(6) 分析結果の解釈を容易にするため、トピックごとの単語の意味合いから、トピックの特徴を表す名前を決定する
概念図
商品/デモ
作成中
関連情報
お問い合わせは、下記ボタンよりお問い合わせください。
株式会社アイズファクトリー

世界を革新する挑戦者に、成功を支援する会社
情報通信業
- 株式会社アイズファクトリー