
名寄せとは
企業が営業活動を行ったり、システムの改善を行ったりすると、システム上に重複したデータが生まれます。「名寄せ」とは、データの重複をなくし、データを正確に保持するための技術です。 「顧客データが大量にあって手がつけられない」「顧客データの重複をなくしたい」「M&Aをしたので、データの統合がしたい」などの悩みを解決することができます。 名寄せを行うことで、正確な顧客データ分析、データ利用の効率化、リスク管理のためのデータクレンジング処理等が可能です。 一般的には、辞書を用いた「完全一致」のマッチング結果で重複を判定します。 しかし、辞書を使った「完全一致方式」の名寄せでは、結果の精度に限界が生じます。例えば、入力ミスの多いデータでは、名寄せは上手く機能しません。また、辞書に依存するため、特殊なデータ項目には対応することが難しくなります。
名寄せエンジン
[1] アイズファクトリー「名寄せエンジン」の強み- 入力ミス・データの名寄せに強い
名寄せキー項目文字列の類似度を算出し、同一かどうかをスコア(確率)で判定します。入力ミス等の曖昧性への対応には不可欠の機能です。 - 自由な名寄せ項目
辞書に依存しない類似度判定方式なので、住所、氏名、電話番号等の他にも、特殊な商品名や識別番号等でも名寄せが可能です。 - 名寄せ度合いを自由に調整可能
重複度を数値で計算するため、データの性質によって名寄せする・しないの閾値を自由に調整することができます。
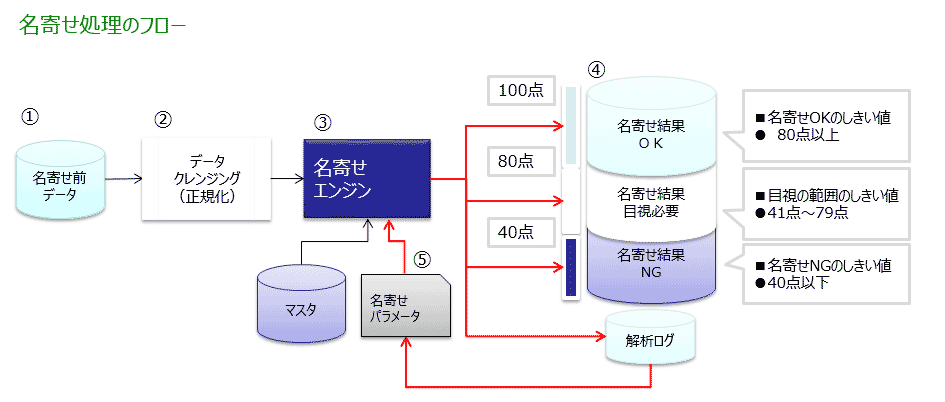
処理フロー
名寄せ前データの項目に合わせて、取り込み様式をカスタマイズします。
データ項目の正規化処理をします。(正規化方針はお打合せ)
名寄せエンジンが重複度の算出(スコアリング)します。
名寄せ結果から、3つのグループに仕分けします。そのためのしきい値も検証し、確定します。
名寄せ結果から、名寄せエンジンのパラメータをチューニングします。
再度処理①~⑤を実施し、再度チューニングし、最適なパラメータを決定します。
※重複度とは、レーベンシュタイン距離(後述)をもとに、弊社独自のアルゴリズムにより重み付けを行い、項目同士の類似性を100点満点で評価したもの
[3] 名寄せの「機能」
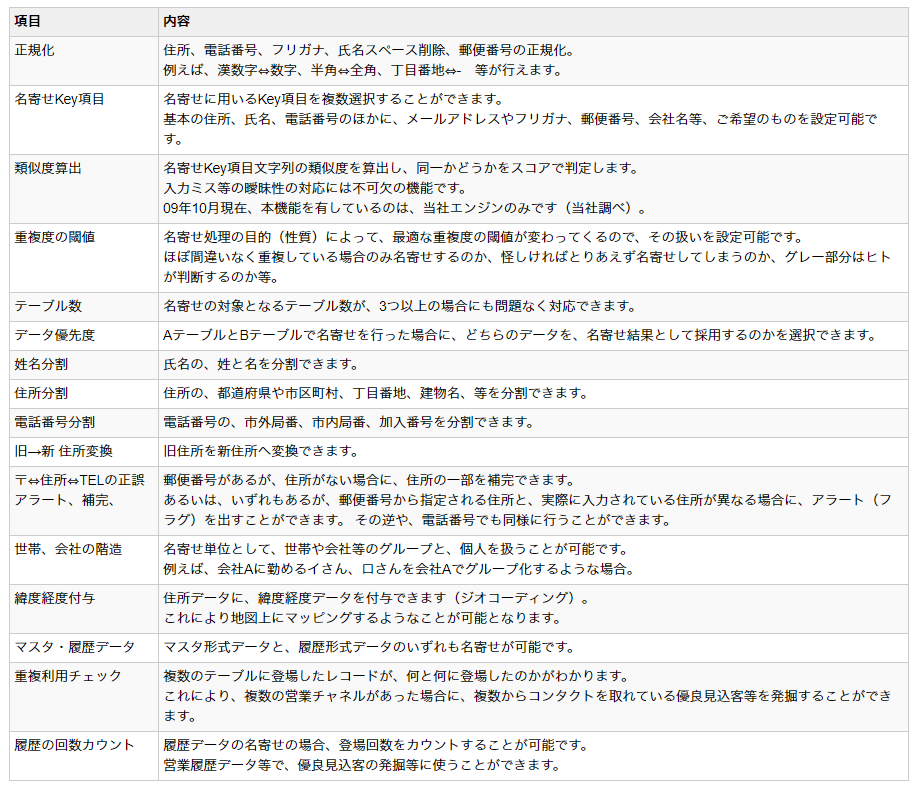
正規化処理
半角全角やハイフン等の表記ゆれに左右されずに名寄せ処理を行う事ができます。
重み付け
名前、住所、電話番号など、複数のデータそれぞれに重み付けをすることが可能です。
重複度判定
重複度の値がしきい値以上である場合、削除処理を行い、削除されたレコードは重複リストに書き出されます。
編集距離計算
各カラムに対して編集距離を計算し、類似度判定を行います。
- 編集距離とは2つ以上の文字列がどの程度異なっているかを示す数値です。
- 空のカラムがある場合は、計算方法を変更し、適切な編集距離を算定します。
重複度計算
各カラムごとに、重複度の重みづけが可能です。
- 計算された各カラムの編集距離を文字列長の長い方のバイト数で規格化します。
- 各カラムの重み比を設定し、重複度を計算いたします。
- 削除処理を行い、削除されたレコードは重複リストに書き出されます。
概念図

技術仕様
商品/デモ
名寄せサービスのデモをASPでご提供しています。サンプルデータもご用意しております。
お問い合わせは、下記ボタンよりお問い合わせください。
株式会社アイズファクトリー

世界を革新する挑戦者に、成功を支援する会社
情報通信業
- 株式会社アイズファクトリー