
ナレッジ概要
テキストマイニングのマイニング(mining)とは、「発掘(Mine)」という意味で、テキストの山から価値ある情報を掘り出す、といった意味が込められています。価値ある情報を発掘するという意味で、データマイニングの手法の一種とも言えます。
日本語は記述上、英語のように単語を分かち書き(文章において語のくぎりに空白を挟んで記述する)をするという習慣はありません。このため、日本語を用いたテキストではまず、定型化されていない文章の集まりを、自然言語解析の手法を使って単語やフレーズに分割します。
その上で単語やフレーズの出現頻度や相関関係を分析して、有用な情報を抽出することになります。
テキストマイニングでは、ルールに従って分析することにより、単語間の関係や時系列の変化などを抽出してゆきます。
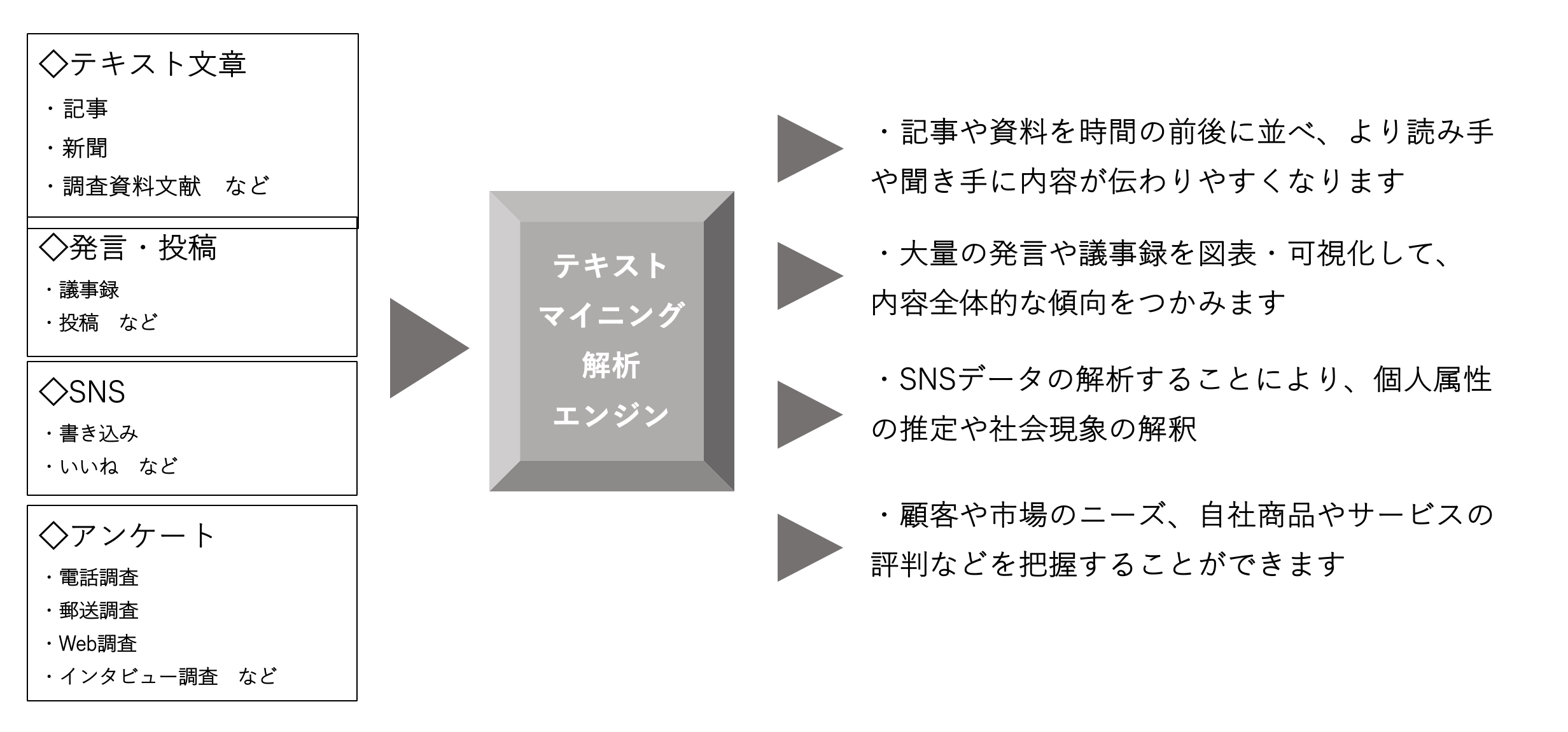
こうして、業務上の問題点を把握したり、製品の評価を調べたり、特に多い問い合わせやクレームを見出したり、さらにこれらが時系列にどう変遷しているかを調べたり、分析・解析することができるようになります。
テキストマイニングでは、膨大に蓄積されたテキストデータを単語やフレーズに分解し、これらの関係を一定のルールに従って分析することにより、単語間の関係や時系列の変化などを抽出していきます。
テキストマイニングの有用性
日本では、業務関連データやデータベース(DB)は数多く存在し、そのほとんどがそのまま自然文のデータ(テキスト文)の蓄積という形で存在しています。
例えば、営業日報や自由記述のアンケート、コールセンターでの顧客とオペレータのやり取りの記録、メーリングリストのログなどです。
これらは意味のある形で数値化や定型化することが難しいため、担当者が一つ一つ目を通して読んで内容を把握して分析することになります。
このため分析・解析するには時間がかかってしまい、DBを効果的効率的に活用することは難しさがたくさんあります。
企業に蓄積されているデータのうち、8割以上がテキストデータであると言われています。
近年、このデータが活用できているか、できていないかが業績に大きく影響するようになってきています。
例えば、アンケートの自由回答やコールセンターのログ、Webサイト上のユーザ書き込み、営業日報などを解析することによって、顧客や市場のニーズを抽出したり、自社商品やサービスの評判を分析したり、業務上の問題点を把握したりすることができます。また、これらが時系列にどう変遷しているかを調べることも可能となっています。
テキストマイニングは、大量の形式化されていないテキスト集合(文書数で数百万)から、自然言語処理の手法によって重要なテキスト群を抽出し、それらをデータマイニングの手法によって解析して、役に立つ知識や情報を獲得する分析手法の総称で、人が読むだけでは得られない、発見的な知識獲得が可能です。
テキストマイニング概念図
お問い合わせは、下記ボタンよりお問い合わせください。
株式会社アイズファクトリー

世界を革新する挑戦者に、成功を支援する会社
情報通信業
- 株式会社アイズファクトリー