昨今改めて注目されている「テキストマイニング」について解析対象の決め方、分析に必要な技術や分析ツールをご紹介
03-5259-9004
特集概略

現代社会ではITシステムの性能が向上し、単体の企業だけで膨大なデータを蓄積できる仕組みが運用されるようになっています。他方で、自社内に留まらず、SNSや公官庁・自治体などがインターネット上で公開しているデータも含め、オープンデータと呼ばれる第三者が提供するデータも大量に存在し、データを活用することの魅力は日に日に増していると考えられます。
そうなると、データが蓄積されているのであれば、有効に活用出来ないか?と考えるのが企業人の性でしょう。ただ、実際にデータを活用したいと考えても、
- 何のために解析するのか?
- どのデータを活用するか?
- どんな技術を使えばよいか?
- どんなツールを使えばよいか?
など、考えるべきことは多岐にわたります。
もちろん、これまでにも述べてきた通り「解析の目的」や「期待する効果」は、解析を行う前に考えておく必要があります。
今回の特集では、「日本語の解析」に特化して、活用できる技術・解析した事例をご紹介させて頂きます。是非、皆様の回りにあるテキストデータの活用のヒントになることを期待しています。 また、本記事の不明点がございましたら、ページ下部にある「お問合せ」からお気軽に一言お声がけください。
§そもそもテキストマイニングとは? wikipedia
・テキストマイニング
「文字列を対象としたデータマイニングのことである。通常の文章からなるデータを単語や文節で区切り、それらの出現の頻度や共出現の相関、出現傾向、時系列などを解析することで有用な情報を取り出す、テキストデータの分析方法である。 テキストデータの多くは形式が定まっておらず、また日本語は英語などと比べて単語の境界判別の必要性(→わかち書き)や文法ゆらぎが大きい点において形態素解析が困難であったが、自然言語処理の発展により実用的な水準の分析が可能となった。テキストマイニングの対象としては、顧客からのアンケートの回答やコールセンターに寄せられる質問や意見、電子掲示板やメーリングリストに蓄積されたテキストデータなどがある。」
出典 テキストマイニング (ウィキペディア)
https://ja.wikipedia.org/wiki/%E3%83%86%E3%82%AD%E3%82%B9%E3%83%88%E3%83%9E%E3%82%A4%E3%83%8B%E3%83%B3%E3%82%B0
テキストマイニングの取り組み方
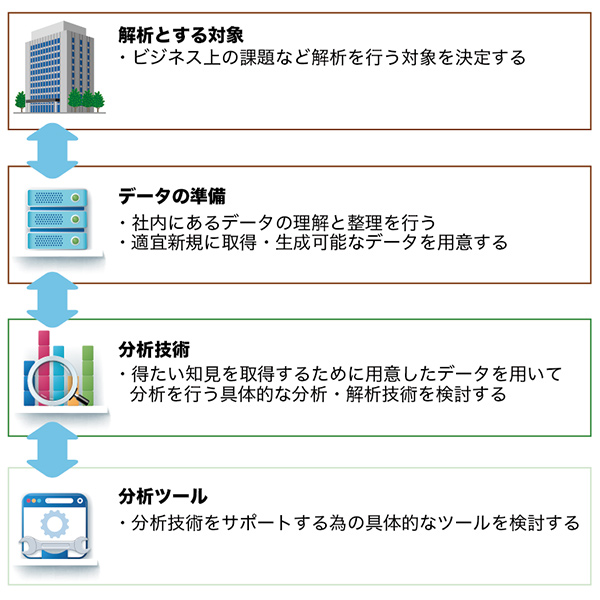
テキストマイニングを行う際には、次の4つの作業に分解すると理解しやすいです。
1.解析とする対象
2.データの準備
3.分析技術
4.分析ツール
1〜4については、以下のリンク先で詳細をご紹介いたします。
1.解析とする対象

bodaisスコアリングのカテゴリ統合
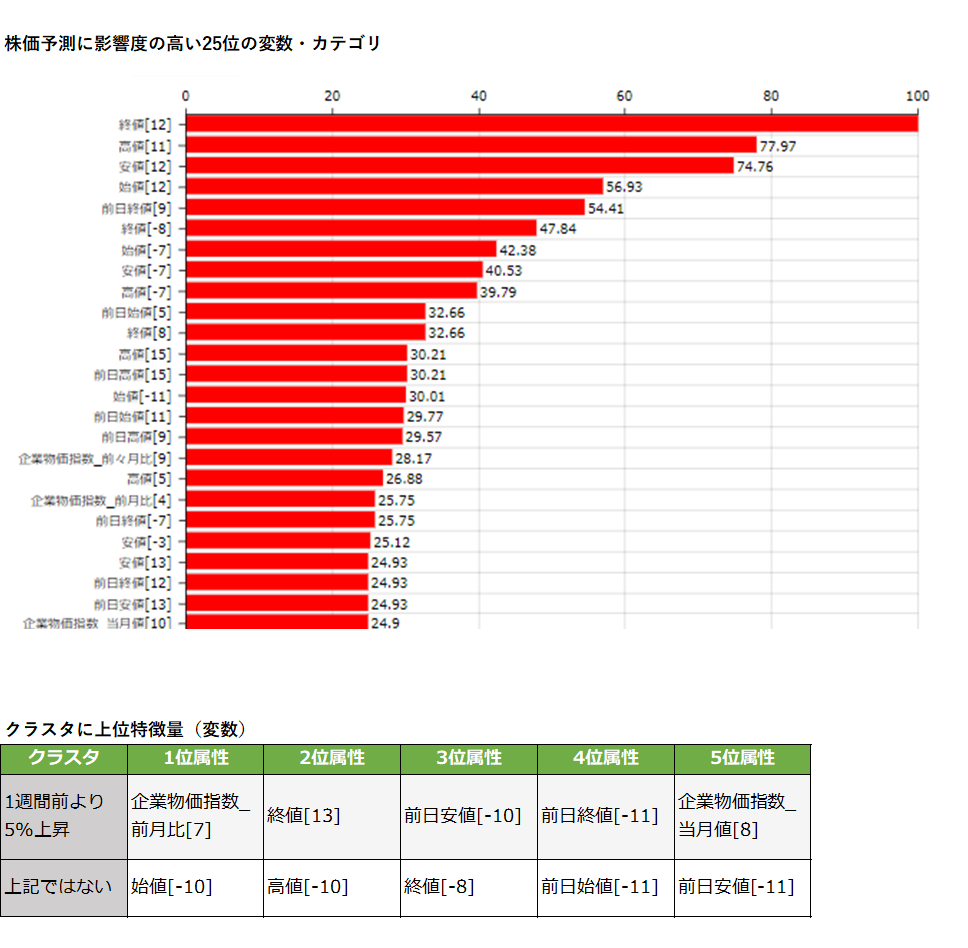
カテゴリカルな説明変数の水準数が過剰になっているデータに対して、適切に水準数を削減する技術をカテゴリ…
技術研究
- 株式会社アイズファクトリー
2.データの準備

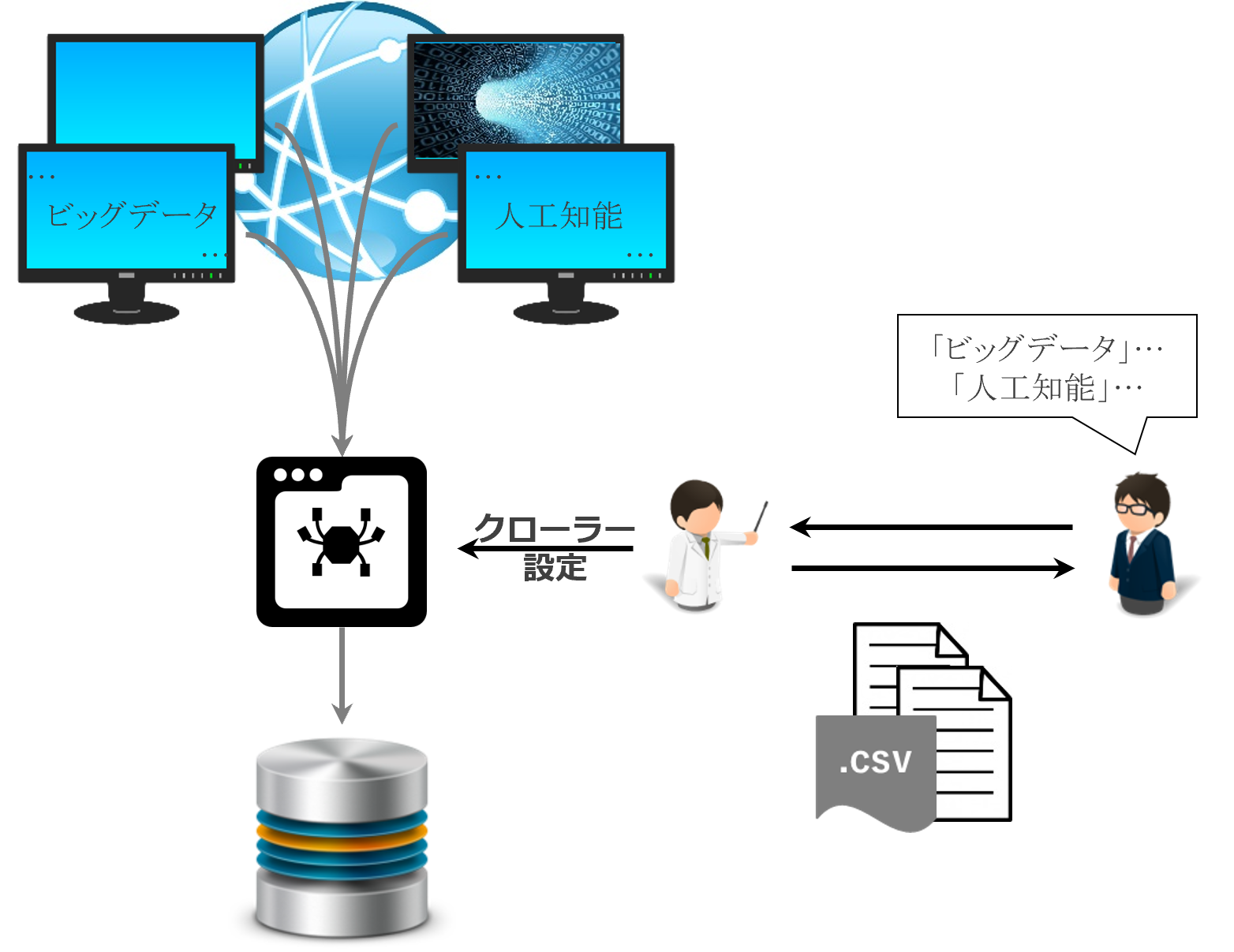
サイトクロール
Webサイトの情報をお客様に代わり収集いたします
データ解析
- 株式会社アイズファクトリー

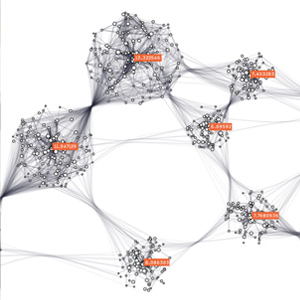
大量文書データの検索・可視化
大量のテキストデータを、キーワードを通じて関係づけて活用しやすくする
データ解析
- 株式会社アイズファクトリー
自然言語処理
【英語】 Natural Language Processing 【読み】 シゼンゲンゴショリ
データ解析
- 株式会社アイズファクトリー
3.分析技術
引用/言及関係解析
特許や論文などの文章群に引用関係を付与します
データ解析
- 株式会社アイズファクトリー
タグ付けアルゴリズム解析
効果的なタグをデータに付与し、データ検索を最適化します
データ解析
- 株式会社アイズファクトリー
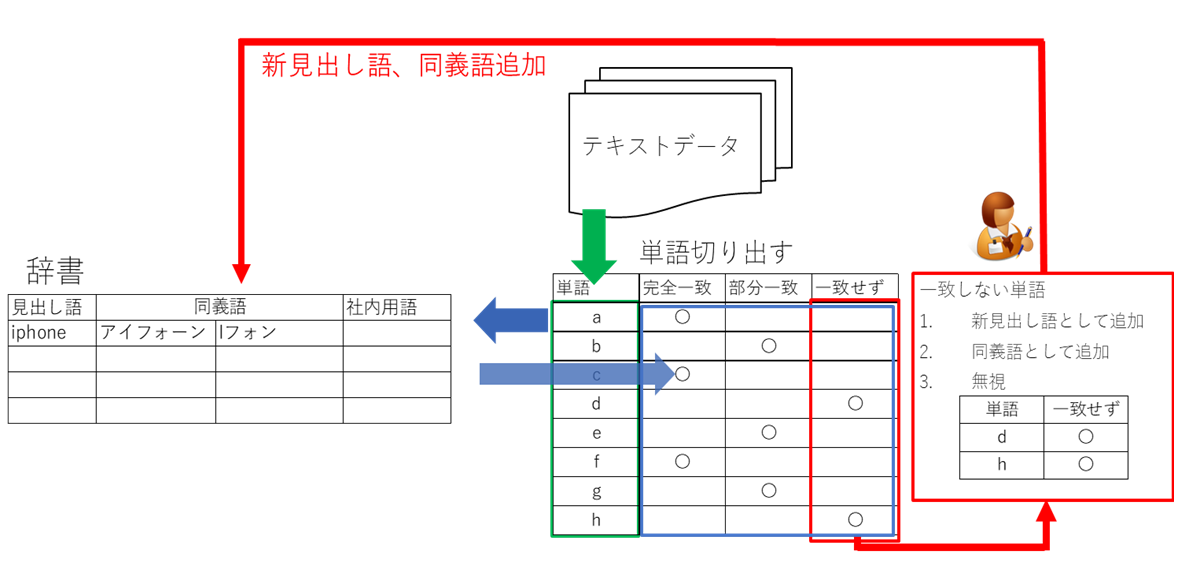
名寄せ
テキストの一致度をスコア化し、精度の高い名寄せを提供
データ解析
- 株式会社アイズファクトリー
不適切用語辞書作成
文章群から作るブラック辞書・ホワイト辞書
データ解析
- 株式会社アイズファクトリー
文書特徴語マップ
ある分野の文章群から特徴のある文章を探し出す
データ解析
- 株式会社アイズファクトリー
CGM見える化
一般の書き込みを地図上に見える化し分析します
データ解析
- 株式会社アイズファクトリー
苦情分類
お客様の声をテキストマイニングで分類し適切な対応を実現します
データ解析
- 株式会社アイズファクトリー
Twitterレポート
Twitterレポートから簡単にレポートが作成できます
データ解析
- 株式会社アイズファクトリー
議事録の集計
議事録のデータを見える化する
データ解析
- 株式会社アイズファクトリー
4.分析ツール
複合語エンジンアプリ
固有の辞書を必要とせずテキストを分割します
アプリ
- 株式会社アイズファクトリー
特徴度エンジンアプリ
文章を特徴づけているキーワードが簡単に抽出できます
アプリ
- 株式会社アイズファクトリー
ポジネガエンジンアプリ
その文章がポジティブか?ネガティブか?を判定します
アプリ
- 株式会社アイズファクトリー
独自検索エンジン
自社専門用語にも対応した独自検索エンジンを構築します
システム
- 株式会社アイズファクトリー
関連用語
テキストマイニング
【英語】 Text Mining 【読み】 テキストマイニング
データ解析
- 株式会社アイズファクトリー
案件化率向上
【英語】 Improvement of Project Conversion Rate 【読み】 アンケンカリツコウジョウ
データ解析
- 株式会社アイズファクトリー
関連事例

メガトレンドの抽出
有識者アンケートの分析によってメガトレンドを抽出
PoC/受託解析
- 公務(他に分類されるものを除く)
不適切なユーザーコメントの自動判定
不適切なユーザーコメントの自動判定によって運用の負荷を軽減
PoC/受託解析
- 情報通信業
クレーム分析
クレームの特徴を分析し、部署ごとの対応スキル・製品の問題などの組織的課題を解決へ
PoC/受託解析
- 製造業